If you’ve ever done a serious web app, you’ve certainly met with a requirement for its monitoring, or tracking various application and runtime metrics. Exploring recorded metrics lets you discover different patterns of app usage (e.g., low traffic during weekends and holidays), or, for example, visualize CPU, disk space and RAM usage, etc. As an example, if the RAM usage graph shows that the usage is constantly rising and returns to normal only after the application restart, there may be a memory leak. Certainly, there are many reasons for implementing application and runtime metrics for your applications.
There are several tools for application monitoring, e.g. Zabbix and others. Tools of this type focus mainly on runtime monitoring, i.e., CPU usage, available RAM, etc., but they are not very well suited for application monitoring and answering questions like how many users are currently logged in, what’s the distribution of server response times, etc.
In this post, I’ll show you, how to do real time runtime and application monitoring using Prometheus and Grafana. As an example, let’s consider Opendata API of ITMS2014+.
Prometheus
Our monitoring solution consists of two parts. The core of the solution is Prometheus, which is a (multi-dimensional) time series database. You can imagine it as a list of timestamped, named metrics each consisting of a set of key=value pairs representing the monitored variables. Prometheus features relatively extensive alerting options, it has its own query language and also basic means for visualising the data. For more advanced visualisation I recommend Grafana.
Prometheus, unlike most other monitoring solutions works using PULL approach. This means that each of the monitored applications exposes an HTTP endpoint exposing monitored metrics. Prometheus then periodically downloads the metrics.
Grafana
Grafana is a platform for visualizing and analyzing data. Grafana does not have its own timeseries database, it’s basically a frontend to popular data sources like Prometheus, InfluxDB, Graphite, ElasticSearch and others. Grafana allows you to create charts and dashboards and share it with others. I’ll show you that in a moment.
Publishing metrics from an application
In order for Prometheus to be able to download metrics, it is necessary to expose an HTTP endpoint from your application. When called, this HTTP endpoint should return current application metrics - we need to instrument the application. Prometheus supports two metrics encoding formats - plain text and protocol buffers. Fortunately, Prometheus provides client libraries for all major programming languages including Java, Go, Python, Ruby, Scala, C++, Erlang, Elixir, Node.js, PHP, Rust, Lisp Haskell and others.
As I wrote earlier, let’s consider ITMS2014+ Opendata API, which is an application written in Go. There is an official Prometheus Go Client Library. Embedding it is very easy and consists of only three steps.
The first step is to add Prometheus client library to imports:
package main
import (
// ...
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
// ...
)
// ...The second step is to create an HTTP endpoint for exposing the application metrics. In this case I use Gorilla mux and Negroni HTTP middleware:
r := mux.NewRouter()
r.Path("/metrics").Handler(promhttp.Handler())
n := negroni.New(negroni.NewRecovery())
n.UseHandler(r)We are only interested in line 2, where we say that the /metrics endpoint will be processed by Prometheus handler, which will expose application metrics in Prometheus format. Something very similar to the following output:
go_goroutines 11
go_memstats_alloc_bytes 7.949552e+06
go_memstats_buck_hash_sys_bytes 2.542265e+06
go_memstats_frees_total 7.49226407e+08
go_memstats_gc_sys_bytes 1.568768e+06
go_memstats_heap_alloc_bytes 7.949552e+06
go_memstats_last_gc_time_seconds 1.5020497859690137e+09
go_memstats_lookups_total 810225
go_memstats_mallocs_total 7.49277644e+08
go_memstats_mcache_inuse_bytes 4800
go_memstats_stack_sys_bytes 819200
go_memstats_sys_bytes 4.0659192e+07
process_open_fds 23
process_resident_memory_bytes 4.3012096e+07
process_start_time_seconds 1.50171016757e+09
process_virtual_memory_bytes 4.42384384e+08In production, you would usually want some kind of access control, for example HTTP basic authentication and https:
r.Path("/metrics").Handler(httpauth.SimpleBasicAuth("USERNAME_NOT_SHOWN", "PASSWORD_NOT_SHOWN")(promhttp.Handler()))Although we have only added three lines of code, we can now collect the application’s runtime metrics, e.g., number of active goroutines, RAM allocation, CPU usage, etc. However, we did not expose any application (domain specific) metrics.
In the third step, I’ll show you how to add custom application metrics. Let’s add some metrics that we can answer these questions:
- which REST endpoints are most used by consumers?
- how often?
- what are the response times?
Whenever we want to expose a metric, we need to select its type. Prometheus provides 4 types of metrics:
- Counter - is a cumulative metric that represents a single numerical value that only ever goes up. A counter is typically used to count requests served, tasks completed, errors occurred, etc.
- Gauge - is a metric that represents a single numerical value that can arbitrarily go up and down. Gauges are typically used for measured values like temperatures or current memory usage, but also “counts” that can go up and down, like the number of running goroutines.
- Histogram - samples observations (usually things like request durations or response sizes) and counts them in configurable buckets. It also provides a sum of all observed values.
- Summary - is similar to a histogram, a summary samples observations (usually things like request durations and response sizes). While it also provides a total count of observations and a sum of all observed values, it calculates configurable quantiles over a sliding time window.
In our case, we want to expose the processing time of requests for each endpoint (and their percentiles) and the number of requests per time unit. As the basis for these metrics, we’ve chosen the Histogram type. Let’s look at the code:
httpDurationsHistogram := prometheus.NewHistogramVec(prometheus.HistogramOpts{
Name: "http_durations_histogram_seconds",
Help: "HTTP request latency distributions.",
Buckets: prometheus.ExponentialBuckets(0.0001, 1.5, 36),
}, []string{"code", "version", "controller", "action"})
prometheus.MustRegister(httpDurationsHistogram)We’ve added a metric named http_durations_histogram_seconds and said that we wanted to expose four dimensions:
code- HTTP status codeversion- Opendata API versioncontroller- The controller that handled the requestaction- The name of the action within the controller
For the histogram type metric, you must first specify the intervals for the exposed values. In our case, the value is response duration. On line 3, we have created 36 exponentially increasing buckets, ranging from 0.0001 to 145 seconds. In case of ITMS2014+ Opendata API we can empirically say that most of the requests only last 30ms or less. The maximum value of 145 seconds is therefore large enough for our use case.
Finally, for each request, we need to record four dimensions we have defined earlier and the request duration. Here, we have two options - modify each handler to record the metrics mentioned above, or create a middleware that wraps the handler and records the metrics. Obviously, we’ve chosen the latter:
func main() {
// ...
api2 := goa.New("API v2")
// Setup middleware
api2.Use(middleware.RequestID())
api2.Use(middleware.LogRequest(false))
api2.Use(prometheusHandler(httpDurationsHistogram))
api2.Use(middleware.Recover())
// ...
}
// ..
func prometheusHandler(hist *prometheus.HistogramVec) goa.Middleware {
return func(h goa.Handler) goa.Handler {
return func(ctx context.Context, rw http.ResponseWriter, req *http.Request) error {
startedAt := time.Now()
err := h(ctx, rw, req)
version := "N/A"
split := strings.Split(req.URL.Path, "/")
if len(split) > 1 {
version = split[1]
}
resp := goa.ContextResponse(ctx)
hist.WithLabelValues(
strconv.Itoa(resp.Status), // code
version, // version
goa.ContextController(ctx), // controller
goa.ContextAction(ctx)). // action
Observe(float64(time.Since(startedAt)) / float64(time.Second)) // request duration seconds
return err
}
}
}As you can see, the middleware is plugged in on line 8 and the entire middleware is roughly 20 lines long. On line 27 to 31, we fill the four dimensions and on line 32 we record the request duration in seconds.
Configuration
Since we have everything ready from the app side point of view, we just have to configure Prometheus and Grafana.
A minimum configuration for Prometheus is shown below. We are mainly interested in two settings, how often are the metrics downloaded (5s) and the metrics URL (https://opendata.itms2014.sk/metrics).
global:
scrape_interval: 5s
evaluation_interval: 5s
scrape_configs:
- job_name: 'opendata'
metrics_path: /metrics
scheme: https
static_configs:
- targets: ['opendata.itms2014.sk']
basic_auth:
username: 'USERNAME_NOT_SHOWN'
password: 'PASSWORD_NOT_SHOWN'A minimal Grafana configuration:
#################################### Paths ####################################
[paths]
data = /var/db/grafana/
logs = /var/log/grafana/
plugins = /var/db/grafana/plugins
#################################### Server ####################################
[server]
protocol = http
# The http port to use
http_port = 3000
# The public facing domain name used to access grafana from a browser
domain = metrics.itms.redbyte.eu
root_url = https://metrics.itms.redbyte.eu/Note: As we can see, a NON TLS port 3000 is exposed, but don’t worry there is a NGINX in front of Grafana listening on port 443, secured by Let’s Encrypt certificate.
Monitoring
Finally, we get to the point where we have everything we need. In order to create some nice charts it is necessary to:
- Open a web browser and log into Grafana
- Add Prometheus data source
- Create dashboards
- Create charts
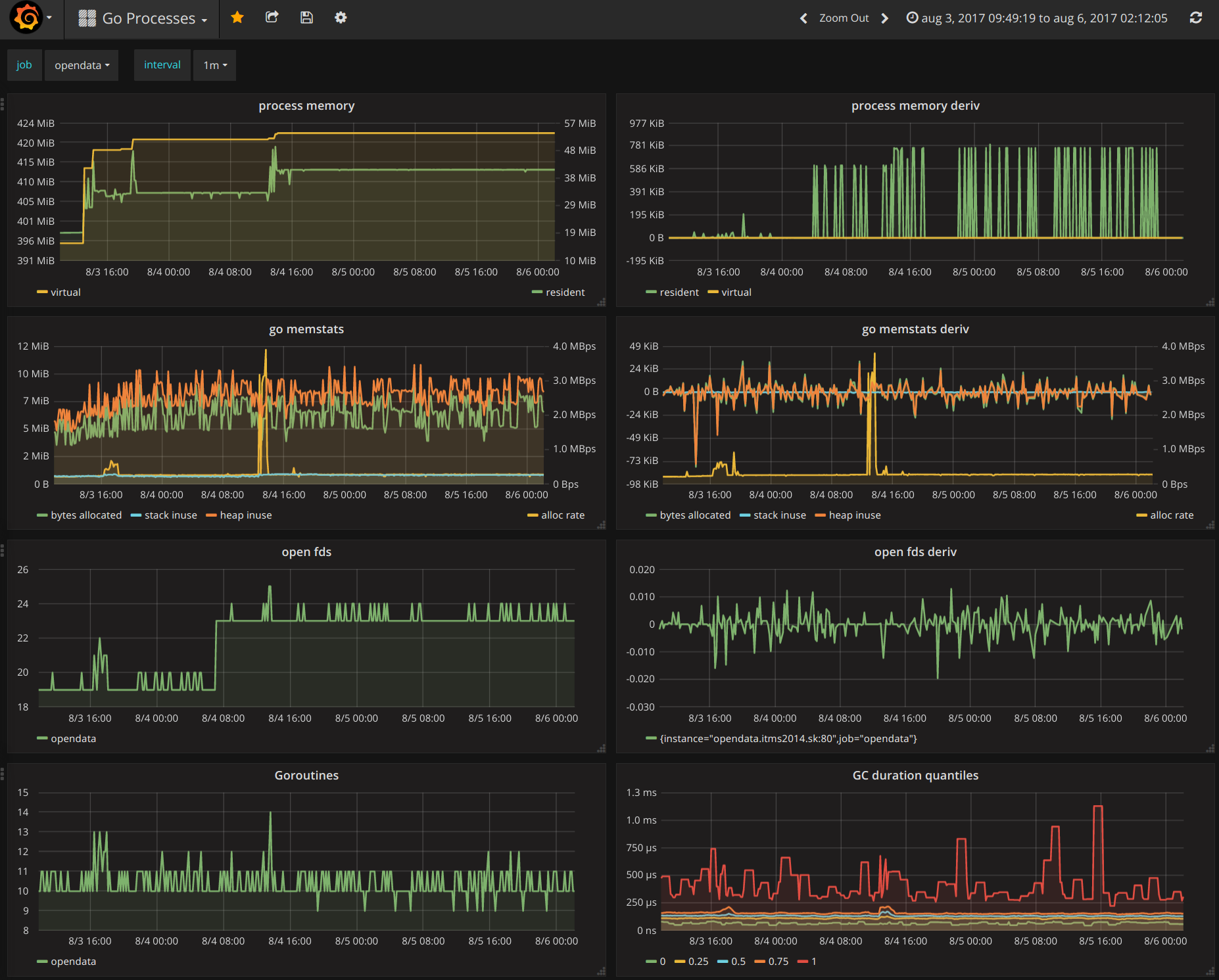
An example of how to create a chart showing the number of HTTP requests per selected interval is shown on the following figure.

Similarly, we’ve created additional charts and placed them in two dashboards as shown on the following figures.

Summary
In this post, we have shown that the application and runtime monitoring may not be difficult at all.
Prometheus client libraries allow us to easily expose metrics from your applications, whether written in Java, Go, Ruby or Python. Prometheus even allows you to expose metrics from an offline applications (behind corporate firewalls) or batch applications (scripts, etc.). In this case, PUSH access can be used. The application then pushes metrics into a push gateway. The push gateway then exposes the metrics as described in this post.
Grafana can be used to create various charts and dashboards, that can be shared. Even static snapshots can be created. This allows you to capture an interesting moments and analyze them later.